An Ultimate Guide to Matrices in GitHub Actions, from Basic to Advanced

Listen, I feel the boldest of girls for calling this an ultimate guide. But it's just because this will be the one post about matrices I'll update over time as I experience more. All info in a single place for easier retrieval, enjoy!
Matrices keep workflows DRY: you setup a job once and let the matrix do the boring work of multiplying it with all the different configurations required.
An Ultimate Guide
- Basics: Simple Matrix
- Multidimensional Matrices (Matrix with Multiple Keys)
- Adjusting matrices with
include&exclude, part I: the "odd job" - Adjusting matrices with
include&exclude, part II: the small print - Case Study: More Complex Matrices
- Simplifying "particular combinations" in matrices
- Handling glitches in the matrix
- WIP Sections
To walk through matrices features, we'll start from a base case and build up from there. If you're completely new to matrices, I recommend you start from the beginning. If you're looking for a specific feature, feel free to jump to the section you need.
(...)
jobs:
unit-tests:
strategy:
matrix:
node-version: [16, 18]
runs-on: ubuntu-latest
steps:
- name: Checkout
(...)
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v4
with:
node-version: ${{ matrix.node-version }}
(...)
Basics: Simple Matrix
What problem do matrices solve? They are used to run the same job multiple times, each time with a different configuration. This reduces mantainability, readability and helps with consistency across jobs.
How to set up a matrix?
Matrices are set at the job level, under the strategy key. Then, at the step level, matrix values are referenced with the ${{ matrix.key_name }} syntax.
Let's go with the classic workflow example, of course: running CI tests in different versions of Node.js.
Show code
(...)
jobs:
unit-tests:
strategy:
matrix:
# I named it `node-version`, but you can name it however you want
node-version: [16, 18]
runs-on: ubuntu-latest
steps:
- name: Checkout
(...)
# And to reference it, use `${{ matrix.key_name}}`
- name: Use Node.js ${{ matrix.node-version }}
uses: actions/setup-node@v4
with:
node-version: ${{ matrix.node-version }}
(...)
Show pipeline
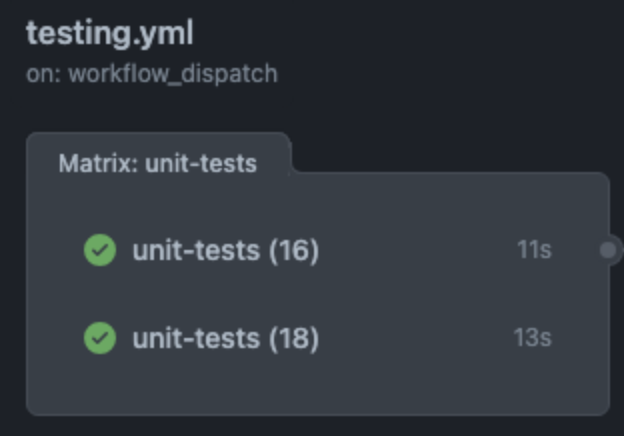
Multidimensional Matrices (Matrix with Multiple Keys)
Of course this can get more complex. To run tests in Node.js 16 & 18, and test each node version in a different OS, you can use a matrix with multiple keys (aka matrix of matrices, or multidimensional matrices).
If we specify two node versions and two OSs, like this...
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16, 18]
... we'll end up with 4 jobs (2*2):
- ubuntu-latest + node 16
- ubuntu-latest + node 18
- windows-latest + node 16
- windows-latest + node 18
Show code
(...)
unit-tests:
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16, 18]
runs-on: ${{ matrix.os }}
steps:
- name: Checkout
(...)
- name: Use Node.js ${{ matrix.node-version }} in ${{ matrix.os }}
uses: actions/setup-node@v2
with:
node-version: ${{ matrix.node-version }}
(...)
Show pipeline
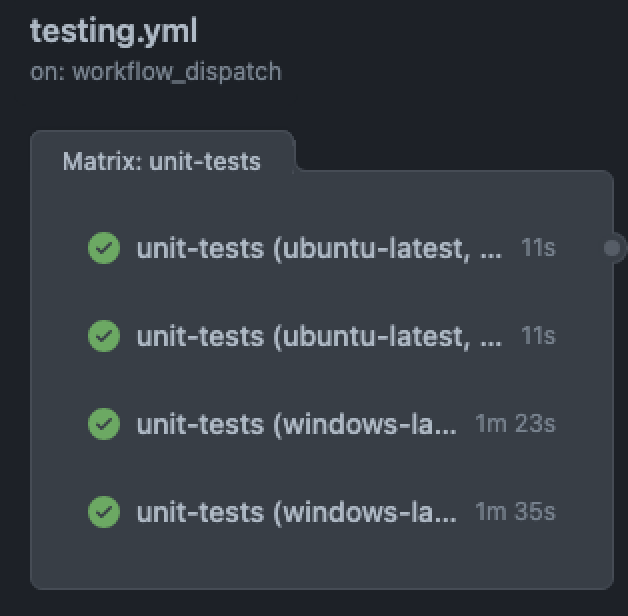
In a matrix of matrices, the number of jobs is the product of the matrix sizes - that is, the number of items in matrix A multiplied by the number of items in matrix B.
This means that the number of jobs can grow exponentially. For example, a matrix with 4 keys where each key has 3 values will end up with 81 jobs (3*3*3*3).
Adjusting matrices with include & exclude, part I: the "odd job"
Static usage
If you know beforehand all the matrix values required, you can set them statically.
Let's say your team will run tests for Node.js 18 in Windows machines. There are two ways to add this case to the existing matrix:
include
With include, you can add an "odd value" to your matrix.
Show code
(...)
unit-tests:
strategy:
matrix:
os: [ubuntu-latest]
node-version: [16, 18]
include: # add the odd combination
- os: windows-latest
node-version: 18
runs-on: ${{ matrix.os }}
(...)
exclude
exclude works in the opposite direction: you add all values to the matrix and use exclude to remove the odd match.
Show code
(...)
unit-tests:
strategy:
matrix:
os: [ubuntu-latest, windows-latest]
node-version: [16, 18]
exclude: # remove unwanted combination
- os: windows-latest
node-version: 16
runs-on: ${{ matrix.os }}
(...)
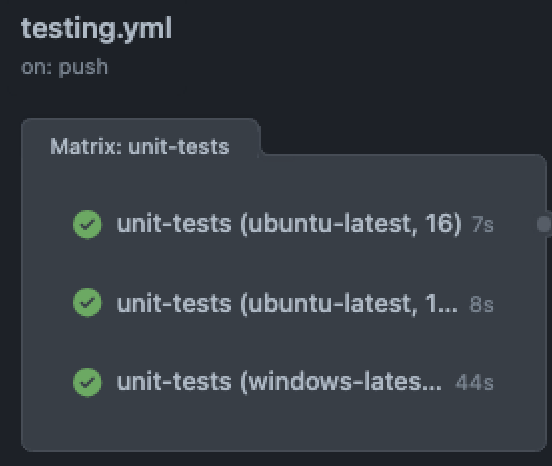
Show pipeline: the pipeline looks the same in both cases
Now there are only 3 jobs:
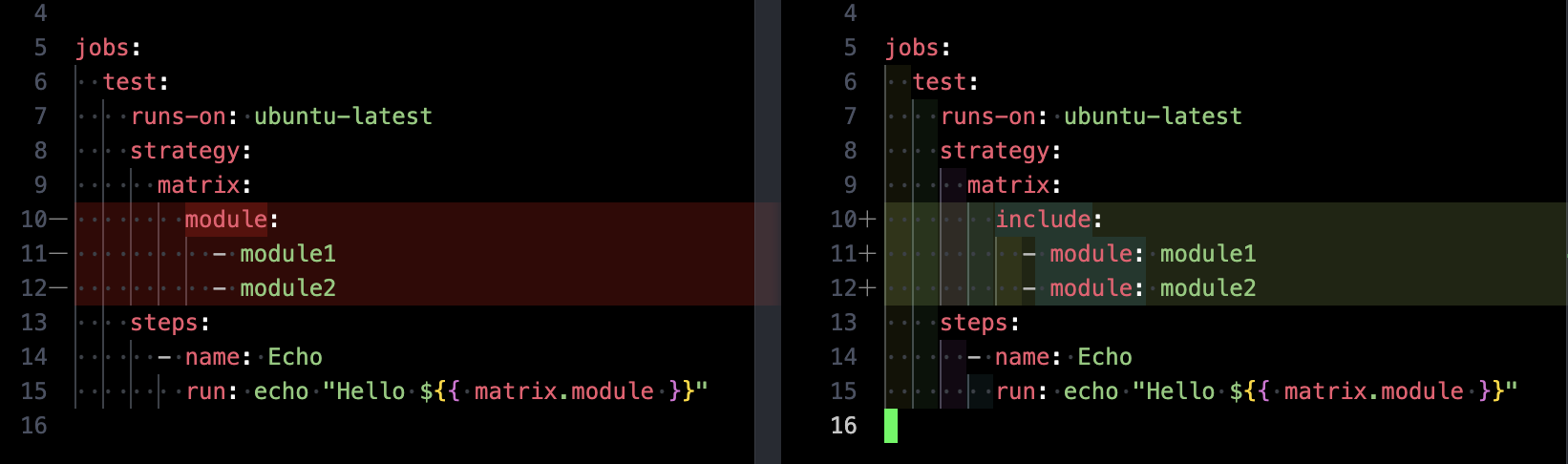
The Declarative Case: include as a flattenning tool
If you prefer clarity over brevity, you can use include to flatten matrices. The example below is too simple to make a case for declarative syntax, but you'll see the appeal as the matrix grows more complex.
Show code
Dynamic Matrices, basic usage
This is my favourite feature: it's possible to dynamically adjust matrix values.
Let's suppose your team decides that every Tuesday you will run tests in Node.js 24, as a peek into changes you'll have to make in the near future. You can dynamically ser that combination only on Tuesdays:
Show code
jobs:
get_weekday:
runs-on: ubuntu-latest
outputs:
WEEKDAY: ${{ steps.get_weekday.outputs.WEEKDAY }}
steps:
- name: Get day of the week
id: get_weekday
run: echo "WEEKDAY=$(date '+%a')" | tee -a "$GITHUB_OUTPUT"
unit-tests:
runs-on: ubuntu-latest
needs: get_weekday
strategy:
matrix:
node-version: [16, 18, 24]
exclude: # remove Node.js 24 from the matrix on all days of the week except Tuesday
- node-version: ${{ needs.get_weekday.outputs.WEEKDAY != 'Tue' && 24 || '' }}
steps:
- name: Run unit tests
run: |
echo "Today is ${{ needs.get_weekday.outputs.WEEKDAY }}."
echo "Let's run tests for Node.js v${{ matrix.node-version }}"
(...)
Show pipeline
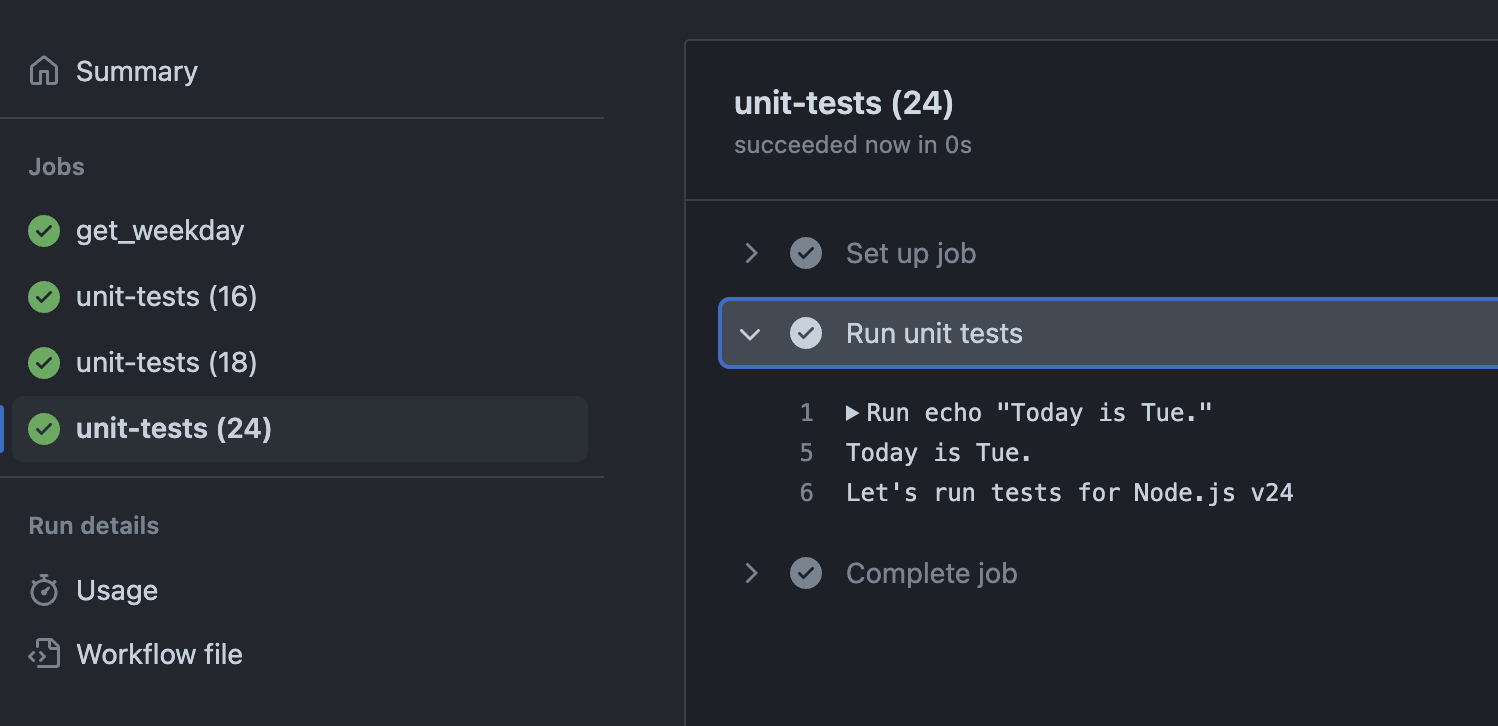
You may have noticed this funny syntax: ${{ needs.get_weekday.outputs.WEEKDAY != 'Tue' && 24 || '' }}. This is a way to use ternaries in Github Actions. If the weekday is not Tuesday, this expression will return 24, meaning that 24 will be excluded from the node-version array values. But, on Tuesdays, this expression will return an empty value => 24 will not be excluded => all node-versions set in the base matrix run => Node.js 24 will run.
Now, why use exclude instead of include?
Honestly, I haven't found a decent way to get included to work in this use case. With include, the syntax would be dreadful. We'd have to use a ternary both for key and value:
include:
- { "${{needs.get_weekday.outputs.WEEKDAY != 'Tue' && 'node-version' || ''}}": "${{needs.get_weekday.outputs.WEEKDAY != 'Tue' && 24 || ''}}" }
You sure you want... this? I sure don't.
Adjusting matrices with include & exclude, part II: the small print
What include doesn't do
First, let's see what you cannot/should not do with include:
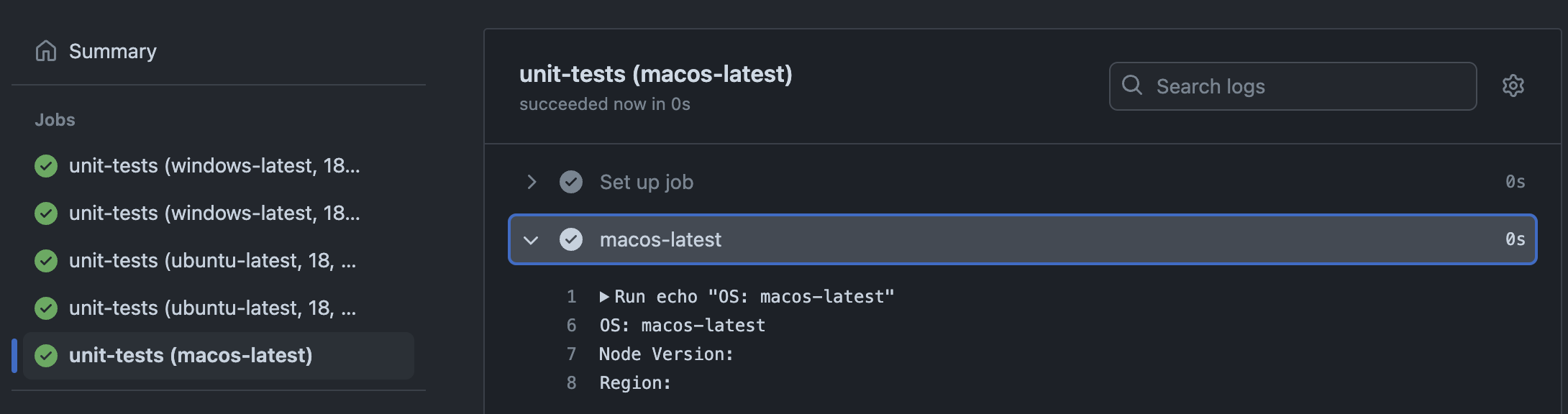
include doesn't inherit the matrix key/value pairs
Just because a key/value pair is present in a base matrix, it doesn't mean include inherits it.
strategy:
matrix:
os: [windows-latest, ubuntu-latest]
node-version: [18]
region: [Asia, Latam]
include:
- os: macos-latest
steps:
- name: ${{ matrix.os }} ${{ matrix.node-version }} ${{ matrix.region }}
run: |
echo "OS: ${{ matrix.os }}"
echo "Node Version: ${{ matrix.node-version }}"
echo "Region: ${{ matrix.region }}"
In this example, because you haven't defined a node-version or region in your include map, those values will be empty in the included job.
If you want to add a new OS that works with the existing node-version and region values, do the obivous thing: add it to the base matrix os array. (Don't ask how I know this.)
Show pipeline
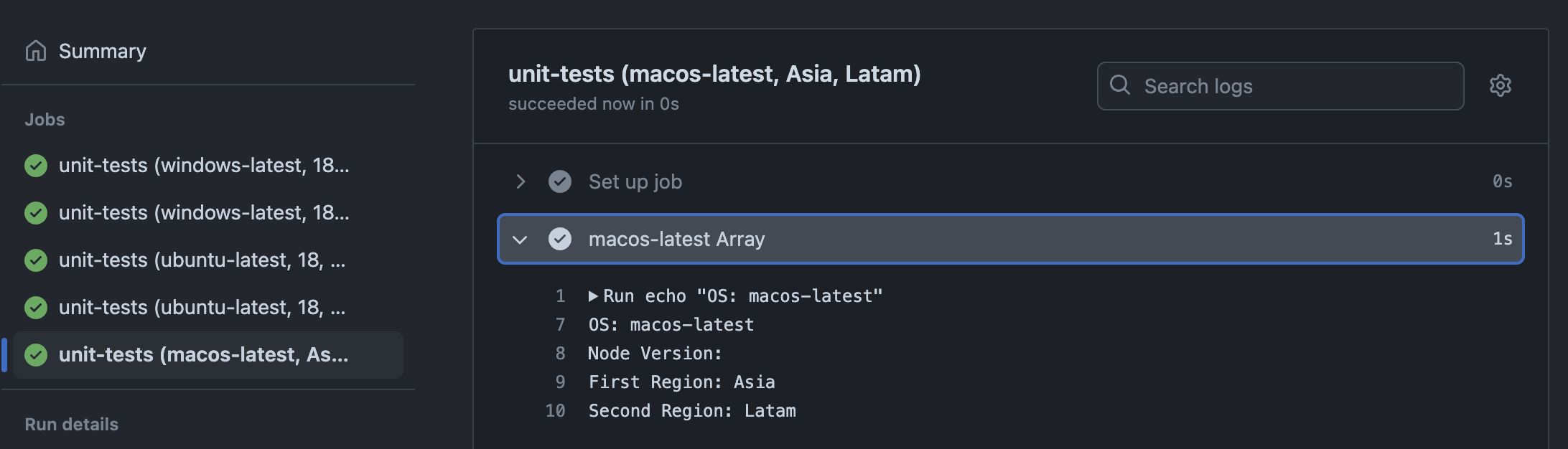
Array values for include do not spread into separate jobs
In this example, the region array will not spin a macos-latest job for each region. include will spin a single MacOS job that takes the whole array as the value for region, printed as Array as you can see in the screenshot below. It's possible, however, to extract the values from the array using the bracket notation matrix.region[0].
strategy:
matrix:
os: [windows-latest, ubuntu-latest]
node-version: [18]
region: [Asia, Latam]
include:
- os: macos-latest
node-version: 20
region: [Asia, Latam]
steps:
- name: ${{ matrix.os }} ${{ matrix.region }}
run: |
echo "OS: ${{ matrix.os }}"
echo "Node Version: ${{ matrix.node-version }}"
echo "First Region: ${{ matrix.region[0] }}"
echo "Second Region: ${{ matrix.region[1] }}"
Show pipeline
Advice for usinginclude
Now, what you can/must do with include, some of which you might have guessed already from the previous points.
Be explicit about all desired key/value pairs
If you want a key/value pair to feature in include, well... include it. It won't magically appear by inheritance.
strategy:
matrix:
os: [windows-latest, ubuntu-latest]
node-version: [18]
region: [Asia, Latam]
include:
- os: macos-latest
node-version: 20
region: Asia
steps:
- name: ${{ matrix.os }} ${{ matrix.node-version }} ${{ matrix.region }}
run: |
echo "OS: ${{ matrix.os }}"
echo "Node Version: ${{ matrix.node-version }}"
echo "Region: ${{ matrix.region }}"
Each include map is a unit
In the previous example, the job added via include (macos-latest) run with a single region value, Asia. What if you want it to run in multiple regions?
You cannot use an array in this case, like we do with base matrices - that's not how include works. To run that job for each region value, you have to add a new map to each required region:
strategy:
matrix:
os: [windows-latest, ubuntu-latest]
node-version: [18]
region: [Asia, Latam]
include:
- os: macos-latest
node-version: 20
# region: [Asia, Latam] <== It won't spin two jobs! It will only pass the data [Asia, Latam] down to the job
region: Asia # spin a `macos/node20` job for Asia
- os: macos-latest
node-version: 20
region: Latam # spin a `macos/node20` job for Latam
steps:
- name: ${{ matrix.os }} ${{ matrix.node-version }} ${{ matrix.region }}
run: |
echo "OS: ${{ matrix.os }}"
echo "Node Version: ${{ matrix.node-version }}"
echo "Region: ${{ matrix.region }}"
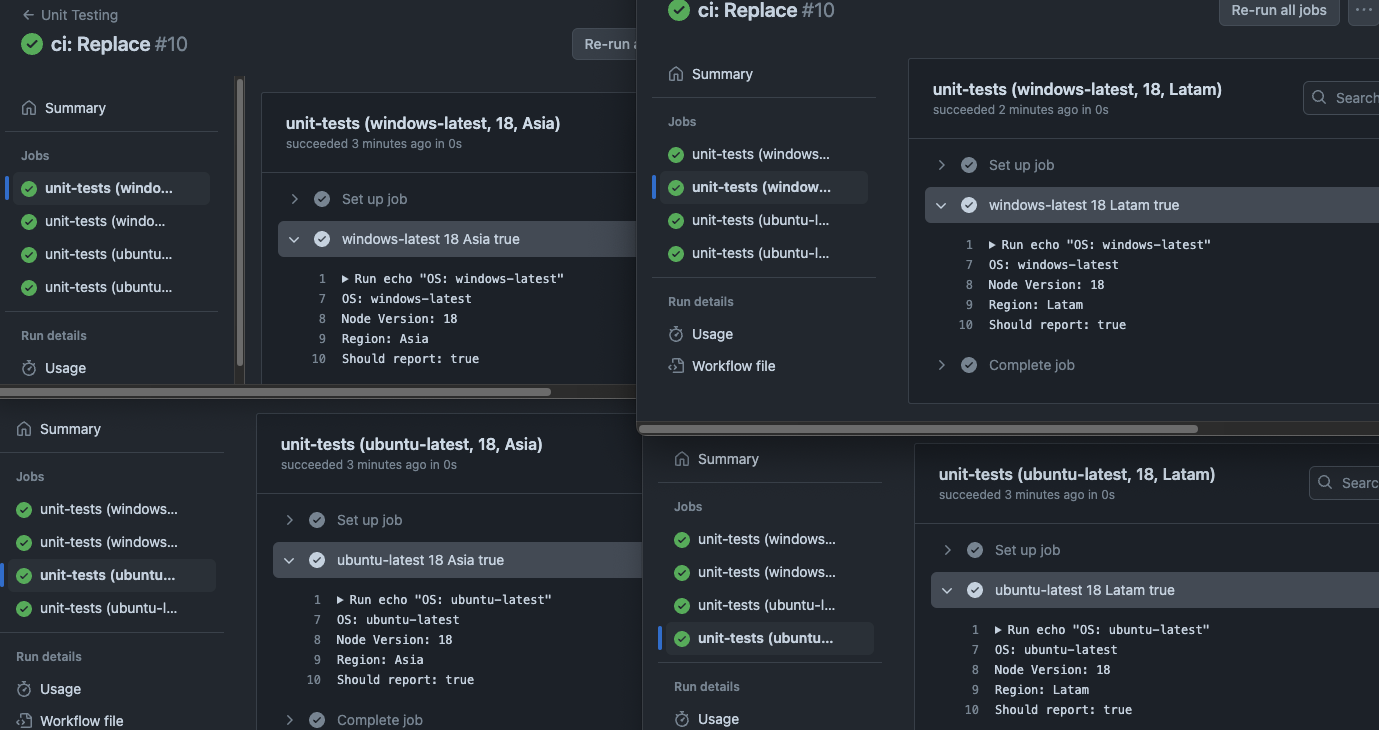
Feel free to add brand new keys not present in the base matrix
When using include, you're not restricted to the already existing keys in the base matrix. New ones can be added, just keep in mind that "new" keys will be added to all jobs in the matrix.
strategy:
matrix:
os: [windows-latest, ubuntu-latest]
node-version: [18]
region: [Asia, Latam]
include:
- report: true
steps:
- name: ${{ matrix.os }} ${{ matrix.node-version }} ${{ matrix.region }} ${{ matrix.report }}
run: |
echo "OS: ${{ matrix.os }}"
echo "Node Version: ${{ matrix.node-version }}"
echo "Region: ${{ matrix.region }}"
echo "Should report: ${{ matrix.report }}"
Show pipeline
Repating, just to highlight it:
- When the keys of an
includemap don't match any existing keys in the base matrix (as in the example above), that new key will be added to every job in the matrix.
Case Study: More Complex Matrices
When real life complexity knocks at your door, include and exclude can become confusing. Let's walk through an implementation example to reason through your options.
Scenario: you need to run tests for your product, but different regions have different requirements for the test suite. But they have one thing in common: both regions require that you produce a report for all tests. Here are your specs:
Asia Region:
- run tests for Node.js 18 in Ubuntu and Windows
- run tests for Node.js 20 in Ubuntu and MacOs
Latam Region:
- run tests for Node.js 18 in Ubuntu and Windows
- run tests for Node.js 20 in Ubuntu only
- run tests for Node.js 22 in Windows, Ubuntu and MacOs
Export test report:
- All tests should output a report.
For clarity, I'll spell out what jobs will run for each product:
| Config | Windows | Ubuntu | MacOs |
|---|---|---|---|
| Region: Asia | 18 | 18, 20 | 20 |
| Region: Latam | 18, 22 | 18, 20, 22 | 22 |
The declarative approach
With this approach, you make each combination very explicit. It's quite easy to see how this can get verbose as your test suite grows.
But there's a silly trick to make it less awful to read: just tweak the include syntax using curly brackets. This is my favourite notation for matrices, as the visual pattern makes the reading more manageable.
Show code
(...)
unit-tests:
strategy:
matrix:
include:
- {os: windows-latest, node-version: 18, region: Asia, report: true}
- {os: windows-latest, node-version: 18, region: Latam, report: true}
- {os: windows-latest, node-version: 22, region: Latam, report: true}
- {os: ubuntu-latest, node-version: 18, region: Asia, report: true}
- {os: ubuntu-latest, node-version: 18, region: Latam, report: true}
- {os: ubuntu-latest, node-version: 20, region: Asia, report: true}
- {os: ubuntu-latest, node-version: 20, region: Latam, report: true}
- {os: ubuntu-latest, node-version: 22, region: Latam, report: true}
- {os: macos-latest, node-version: 20, region: Asia, report: true}
- {os: macos-latest, node-version: 22, region: Latam, report: true}
runs-on: ${{ matrix.os }}
steps:
- name: Run tests
run: |
echo "Running tests for Node.js ${{ matrix.node-version }} in ${{ matrix.os }} in ${{ matrix.region }}"
echo "Should report: ${{ matrix.report }}"
(...)
The include/exclude approach
Some people might prefer this approach, but it requires a little training to tell what specific jobs will be actually spinned up.
In this example, we will build our base matrix with all configuration settings, and trim down undesired cases:
matrix:
os: [windows-latest, ubuntu-latest, macos-latest]
node-version: [18, 20, 22]
region: [Asia, Latam]
As an exercise, how many jobs do we have there?
os_length (3) * node-version_length (3) * region_length (2) = 18
Then we can proceed to remove the excess.
Keep in mind that include is processed after exclude, so we can use include to add back combinations that were previously excluded.
matrix:
os: [windows-latest, ubuntu-latest, macos-latest]
node-version: [18, 20, 22]
region: [Asia, Latam]
exclude:
- {node-version: 22, region: Asia} # Asia has no case for Node.js 22 (-3 jobs)
- {node-version: 18, os: macos-latest} # MacOs won't test Node.js 18 (-2 jobs)
- {node-version: 20, region: Asia, os: windows-latest} # Windows is the only case without Node.js 20 in Asia (-1 job)
- {node-version: 20, region: Latam} # There's only one case for Node 20 in Latam, we'll re-add it later (-3 jobs)
include:
- {node-version: 20, region: Latam, os: ubuntu-latest} # Re-adding the case for Node 20 in Latam (+1 job)
Show pipeline
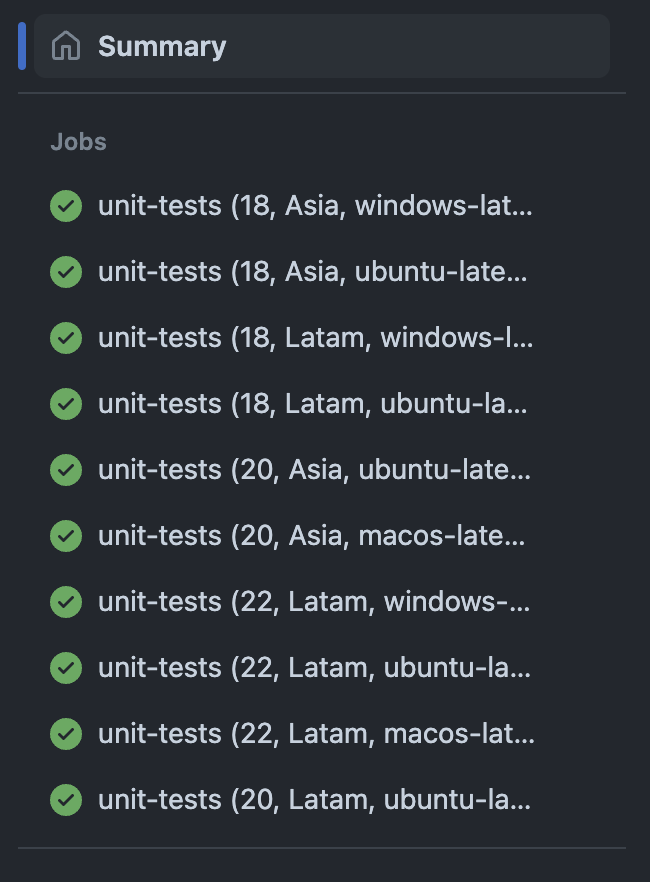
And finally, because the report should be added to all cases, report can go under include:
matrix:
os: [windows-latest, ubuntu-latest, macos-latest]
node-version: [18, 20, 22]
region: [Asia, Latam]
exclude:
- {node-version: 22, region: Asia}
- {node-version: 18, os: macos-latest}
- {node-version: 20, region: Asia, os: windows-latest}
- {node-version: 20, region: Latam}
include:
- {node-version: 20, region: Latam, os: ubuntu-latest}
# doesn't add a new job, just adds `report` to all existing jobs
- report: true
Show pipeline
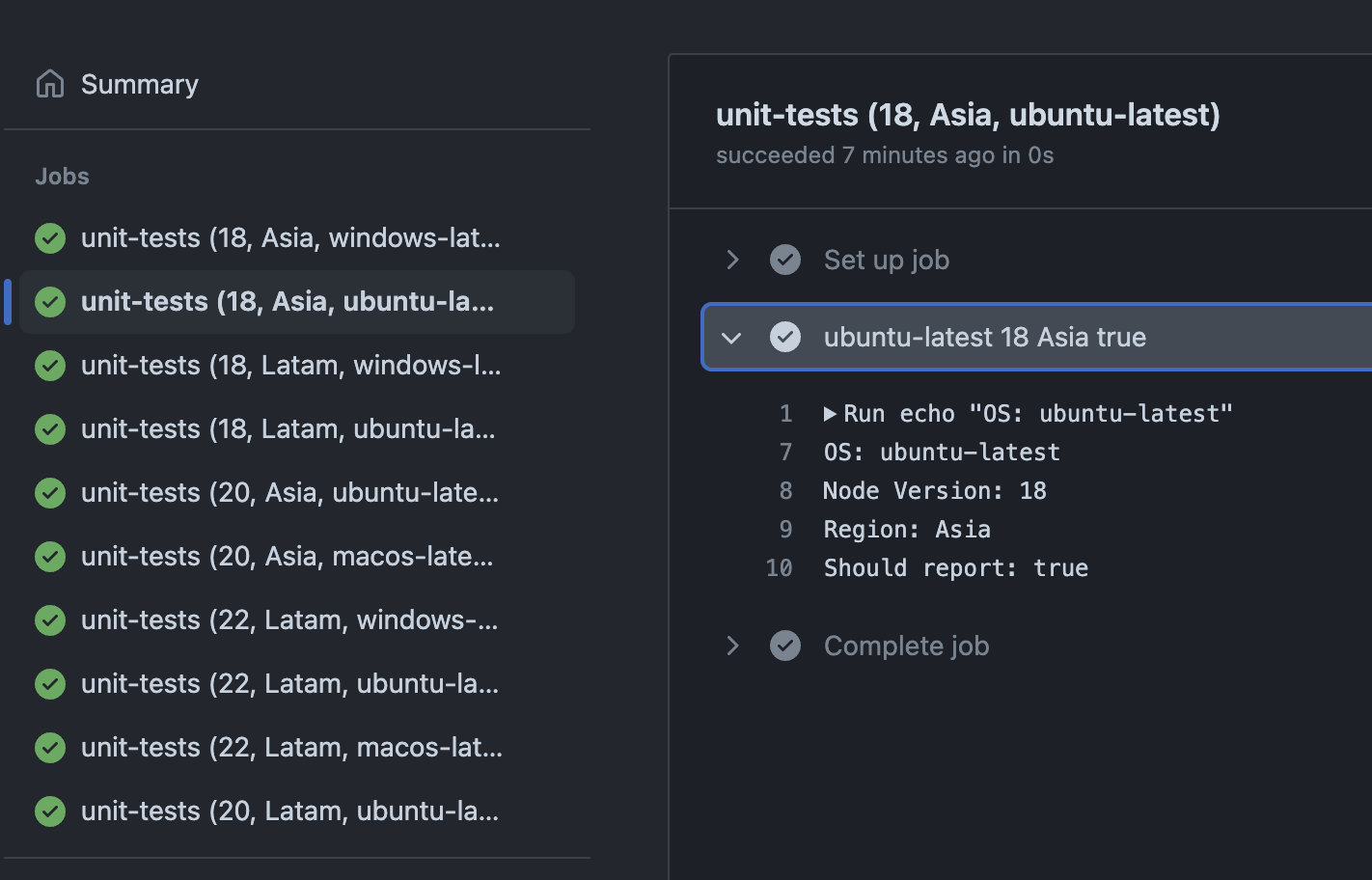
And that's how we end with our 10 desired jobs.
Simplifying "particular combinations" in matrices
If you're using multidimensional matrices, the more configurations you set, the more difficult it is to handle outliers. So here's a trick I learned from Sean Killeen's blog: instead of using include, exclude and whatnot, you can use maps to easily group key/value pairs that usually go together but don't quite fit a matrix logic because they are too tighly coupled.
It won't work for all cases, but will be a good solution for plenty of them:
jobs:
build_release:
name: "Build and Release"
strategy:
matrix:
VERSIONS: [ {ruby: 2.7.3, ghpages: 226}, {ruby: 2.7.4, ghpages: 228}] # tight coupling between ruby and ghpages versions, not very "matrixy"
NODE_MAJOR_VERSION: [16,18,20]
runs-on: ubuntu-latest
env:
NODE_MAJOR_VERSION: ${{ matrix.NODE_MAJOR_VERSION }}
RUBY_VERSION: ${{ matrix.VERSIONS.ruby }}
GITHUB_PAGES_VERSION: ${{ matrix.VERSIONS.ghpages }}
-->
Handling glitches in the matrix
Matrix job failures
It's true that jobs run in parallel and are independent of each other. But, by default, when jobs are spin up by a matrix, all are cancelled if one of them fails. This might not be desirable in all cases, so you can change that behaviour.
| Option | Scope | Effects |
|---|---|---|
fail-fast: <boolean> | Entire matrix | Default: true. Determines if all ongoing and queued matrix jobs will be cancelled if one job fails |
continue-on-error: <boolean> | Job level | Determines if a failure on a job will bypass fail-fast: true |
matrix.experimental: <boolean> | Job level | Allows jobs to have different continue-on-error values |
jobs:
unit-tests:
continue-on-error: false # default value, can be ommited
strategy:
fail-fast: true # default value, can be ommited
matrix:
node-version: [14, 16, 18]
runs-on: ubuntu-latest
steps:
(...)
fail-fast
fail-fast is pretty straightforward: true will short-circuit the matrix if one job fails; false makes all jobs run regardless of other job failures.
continue-on-error
continue-on-error is a way to add an exclusion to the fail-fast setting.
A matrix with fail-fast: true will not fail if continue-on-error is true. The opposite also stands: a matrix with fail-fast: false will fail if continue-on-error: false is set.
If you're not aware, continue-on-error can be used at the step level to prevent a job from failing should that step fail. It can also be used independently of matrices.
When used alone, continue-on-error at best cancel out fail-fast - which is not a big advantage, as you could simply set fail-fast to false. The real leverage comes when matrix.experimental is added to the mix.
matrix.experimental
matrix-experimental allows matrix jobs to have different continue-on-error values. This way, you can granularly define which failing jobs should or shouldn't halt the remaining ongoing & queued jobs.
An example: you are evaluating an unstable Node.js version and you want to low-key observe its behaviour for a while. You don't want the whole matrix to fail if your little unstable experiment fails the tests; you matrix should only fail if stable Node.js versions raise issues.
To exclude that one unstable version from fail-fast, you can include it to the matrix and set it as the only job with an experimental value of true:
Show code
jobs:
unit-tests:
strategy:
runs-on: ubuntu-latest
continue-on-error: ${{ matrix.experimental }} # dynamically set for each job
matrix:
# ommited fail-fast as it's true by default
node-version: [18, 20]
experimental: [false] # will populate continue-on-error with false
include:
- node-version: 21
experimental: true # will populate continue-on-error with true, but only for this job that runs v21.
steps:
(...)
So the resulting continue-on-error settings for this matrix will be:
- node 18, continue-on-error: false
- node 20, continue-on-error: false
- node 21, continue-on-error: true
Dynamically-generated matrices: Handling Empty Matrix Error
(This section will make more sense once I add the section about dynamically-generated matrices)
If you are using dynamically generated matrices, your workflow may fail if the matrix is empty:
Error when evaluating 'strategy' for job 'xxxxx'. .github/workflows/my_worflow.yaml (Line: X, Col: Y): Matrix must define at least one vector
The fix is to execute the dependent job with a conditional:
apply:
name: '${{ matrix.account }}'
needs: generate
if: ${{ fromJson(needs.generate.outputs.matrix).include[0] }}
strategy:
fail-fast: false
matrix:
include: ${{ fromJSON(needs.generate.outputs.matrix) }}
What is happening here?
The conditional converts the JSON string to an object, and checks if the include key has at least one map. Use fearlessly, because matrices contain the includes property whenever a matrix has any elements - it doesn't depend on using he include keyword explicitly on the matrix definition.
WIP Sections
Come back later! I've started drafting content for the following sections:
- Limitations (e.g. Matrix outputs don't work neatly, they require artifacts)
- Dynamically-generated Matrices
- Resource Management: Max Number of Concurrent Jobs
- Advanced use of matrices with reusable workflows
- Sharing a matrix between jobs